Fusion SMB instead of Samba: Why?
Heya folks, it’s Ned Pyle again. Let’s talk about how Tuxera Fusion SMB stacks up to its Linux community alternative, Samba....
We are here to help
Have a question or need guidance? Whether you’re searching for resources or want to connect with an expert, we’ve got you covered. Use the search bar on the right to find what you need.


When AI platforms misbehave in production, the instinct is to buy more GPUs. Many teams are solving the wrong problem.
The real bottleneck may not be compute, but storage. Teams add GPUs, optimize batching, tune the model, and still see latency spike unpredictably, scaling take longer than it should, and workers stall waiting for data. The compute isn’t the constraint; the infrastructure delivering data to that hardware is.
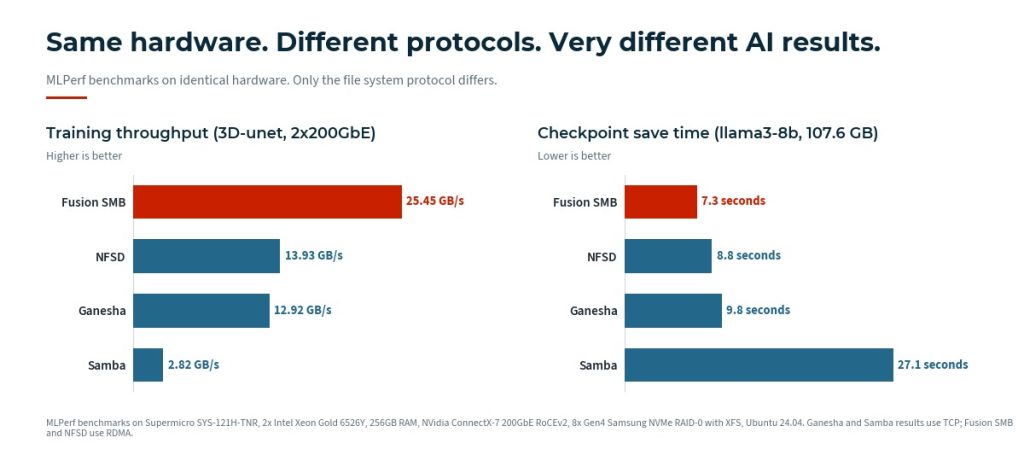
The phase where storage matters most is training. AI training feeds models large datasets of unstructured data: files, documents, and images. It can run for days, weeks, or months. Checkpointing alone creates sustained, intensive storage demand throughout that process. Saving the model’s state at regular intervals so training can resume after failure means the cluster pauses repeatedly to write large amounts of data. In recent MLPerf llama3-8b checkpoint testing, Fusion SMB completed a 107.6 GB checkpoint write in 7.3 seconds; Samba took 27.1 seconds for the same operation. At training scale, that difference compounds across thousands of checkpoints into hours of lost compute time.
After training comes inference. This is the operational phase. The trained model is now responding to live requests. The long, storage-intensive work is complete, though the training data rarely remains static, and the cycle continues as new data is added. Storage still matters at production scale, but the nature of the demand shifts. Rather than sustained data ingestion, the challenge becomes fast, concurrent access across many workers simultaneously.
In both phases, the same underlying problem emerges: dozens, hundreds, or thousands of compute workers need fast, concurrent access to the same data. That’s not a computing challenge; it’s a file access challenge.
The common workarounds each carry hidden costs:
A remote shared file system solves this cleanly: one authoritative copy of each model or dataset, a consistent view across all workers, and fast startup when new nodes come online. No bespoke distribution logic. No synchronization overhead.
A remote shared file system requires a network protocol with enormous throughput and low latency. SMB has been evolving for over 40 years, but the version released in 2012 (SMB 3) is so different from what you saw in the 90s that you could consider it a new protocol.
AI and ML training is not metadata-heavy. Recent MLPerf 3D-unet training results make this concrete: on identical hardware at 2x200GbE, Fusion SMB delivered 25.45 GB/s of training throughput, while NFSD managed 13.93 GB/s and Samba 2.82 GB/s. NFS was designed with metadata performance as a priority. SMB 3, with RDMA, multichannel, and scale-out, was built to move very large amounts of data fast. AI training rewards the latter. Forget what you know about SMB from open source and old Windows environments; this is a different protocol designed for a different job.
Tuxera didn’t alter SMB itself (SMB is an open but Microsoft-owned protocol) but built an exceptionally high-performance implementation that fully realizes SMB 3’s potential. For teams with a Linux background, Samba is usually the reference point for SMB performance, but Samba isn’t representative of what SMB 3 can actually do.
Fusion SMB on Linux is significantly faster than Samba, scales to far more concurrent workers, and outperforms Windows Server’s own SMB implementation on the workloads that matter for AI. It’s the SMB engine behind several leading high-performance storage platforms, including Weka and IBM Storage Scale.
Storage problems in AI infrastructure are rarely visible until they become production incidents. By the time latency is spiking and workers are stalling, the storage layer is already a liability.
Fusion SMB removes storage as a limiting factor, not by introducing an exotic new system, but by delivering shared, predictable, high-performance file access that scales with the workload. It lets teams reuse familiar tools and security models, the ones already governing the rest of their infrastructure, while meeting the performance demands of modern AI at scale.
For teams moving AI from experimentation into production, that means fewer incidents, faster scaling, and a storage layer that simply stops being a problem. Reliability isn’t a nice-to-have. It’s the foundation everything else is built on.
See the benchmarks for yourself
The numbers in this article come from MLPerf testing on a single hardware configuration. Your workload, your network, and your storage will look different. We will run a proof of concept on your infrastructure and share the results.
Talk to a Fusion engineerRELATED ARTICLES

Heya folks, it’s Ned Pyle again. Let’s talk about how Tuxera Fusion SMB stacks up to its Linux community alternative, Samba....

How collaboration with industry leaders is transforming media storage performance Following our award-winning presence at NAB Show 2025, where Tuxera...

Why media workflows demand a new approach to file sharing The media and entertainment industry stands at a technological crossroads....

Mission-critical file sharing for media deployed on-prem, containerized or in the cloud. Tuxera, a leading provider of quality-assured file systems...
Suggested content for: