Zonal architecture storage requirements: what to validate before you trust your SDV
In software-defined vehicles, zonal architecture storage requirements are really requirements for predictable behavior under stress — not peak speed. Here's...
We are here to help
Have a question or need guidance? Whether you’re searching for resources or want to connect with an expert, we’ve got you covered. Use the search bar on the right to find what you need.


Over-the-air updates are now part of the product lifecycle for modern vehicles. They are also one of the most demanding operations an embedded system can perform. The system is rewriting critical state while still having to survive real power behavior, real write loads, real timing constraints, and real recovery conditions.
An over-the-air update, shortened to OTA after definition, is a system update delivered to the vehicle over a network connection. A firmware update or software package is downloaded, verified, installed, and validated as part of the update process.
When that process fails in the field, the failure rarely stays contained. The symptoms are familiar: boot loops, rollback loops, partial functionality, or a unit that never comes back without physical access. Teams often start by looking at delivery, signing, and packaging because those are visible and measurable.
Those areas matter. But a common class of bricking outcomes is tied to storage behavior during interruption and recovery. This becomes more likely as devices age, and the write profile looks nothing like a clean bench test. In other words, the real world is harsher than the lab.
As vehicles move toward higher autonomy, this matters more. The physical AI data layer is the full sensor-to-action data path where determinism, integrity, and recoverability either hold under real-world stress over the device lifetime or fail. At fleet scale, that reliability becomes a major driver of cost and risk. OTA updates are one of the most frequent stress tests of that layer.
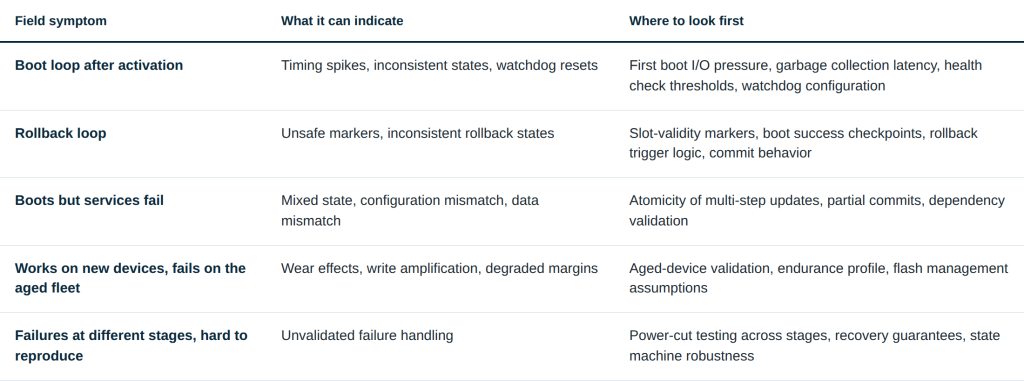
Bricking is often used as a catch-all term. The symptom pattern matters.
A unit might never complete boot after activation. It might reset repeatedly during startup. It might keep rolling back even when a previous image should be valid. Or it might boot, but critical services never come up because the configuration or state is inconsistent.
The common thread is simple: the update pipeline left the system in a state it cannot interpret confidently, and the recovery model did not pull it back to a known-good baseline. In vehicles, that does not always mean the image itself is bad. It can mean the system cannot trust the state that decides what to boot, what to roll back to, or whether the update actually succeeded.
Most OTA update pipelines follow the same broad sequence:
Storage risk exists at every step where critical writes happen, not only at install time.
Many update failure incidents start earlier than installation. A bad download caused by an unstable connection, for example over cellular or Wi-Fi, or by issues along the network path such as a gateway or proxy, can produce a corrupted update file that continues through the pipeline until validation or first boot.
When that happens, teams often see a generic error message in logs or a user interface message that does not explain the real failure point. Because the update often originates from a backend server, it helps to separate delivery failures, such as download integrity and connectivity, from storage and state failures, such as atomicity, recovery, and determinism.
A staging write interrupted at the wrong moment can be just as damaging as an interrupted activation, a small slot-valid marker that does not commit safely can trigger repeated rollbacks, and a boot that hits timing spikes can look like a broken update even when the image itself is correct.
What matters is whether state transitions remain correct when the system is interrupted, stressed, or aged.
OTA updates touch high-impact states: images, manifests, slot markers, configurations, and boot metadata. If power is interrupted mid-write, the system can end up with partially written data or inconsistent metadata.
On the next boot, the system has to infer what happened. This is where loops and dead ends appear. This is also where bricking risk increases.
The core question is not whether the system can write fast. It is whether the system can recover predictably after an interruption. A safe storage layer returns to a known-good state without manual repair steps. It does this repeatedly.
Power-loss failures happen not only during the large image write. They also happen during small writes. Slot markers, boot success flags, health checkpoints, and rollback triggers are small, but they control whether the device escapes a loop or stays trapped in it.
In the field, power instability can trigger an unexpected reboot. It can also trigger repeated restarts during installation. That is why power-safe commit behavior needs to be designed and tested, not assumed.
Battery behavior also matters. A low battery condition can behave like a brownout. That can happen during an update window, especially if the system is under load.
Updates rarely change one thing. They change multiple components that must remain consistent: binaries, configuration, dependency state, policies, version markers, and health checkpoints.
If those transitions are not atomic, the system can restart into a mixed state: new markers pointing to old components, old configurations paired with new binaries, or an activation step that completed only halfway.
Mixed states are a common trigger for boot failure and rollback loops. The system has no single version of truth to validate against.
This is also why OTA update failures can look random. The device is not failing in one clear place. It is failing because the update model allowed the state to become internally inconsistent.
OTA update control depends on a small set of state signals. Those signals decide what to boot and whether to roll back: downloaded, applied, boot succeeded, rollback required, slot valid.
Many programs already use dual-slot, or A/B, updates. The concept is that one slot remains active while the other slot is updated. If activation fails, the system can return to the known-good slot. In many designs, the bootloader and update framework own the slot selection, activation, and rollback logic.
That handles the clean case. It does not, on its own, guarantee that the small markers and metadata controlling the switch are written atomically and survive interruption. That gap is where bricking still happens.
When those markers are corrupt or inconsistent, rollback can become unreliable. Teams may see endless retries, repeated rollbacks, or a device that cannot select a valid bootable image even when one exists.
If the system cannot trust those markers, it may select the wrong version or keep retrying the same path. This is how fleets end up seeing the same problem again and again after what looked like a fix.
The important point is that these markers need strong integrity guarantees. Treating them like ordinary file writes can create self-inflicted loops.
OTA updating is write-heavy. It lands on top of the device’s normal write profile: telemetry, event logs, sensor data, caches, and application state.
Put the write load in perspective. An automotive compute unit running full operating system logging, telemetry buffering, OTA staging, and event capture can sit at several to tens of gigabytes per day before any development-vehicle raw capture. That is the baseline the update window lands on top of, and it accumulates over a lifecycle measured in years, not bench-test weeks.
Over time, flash wear changes the reliability profile. Write amplification accelerates it. Many failures only show up on aged devices. That is why “it works in the lab” does not always translate to “it works in the fleet.”
If validation uses only fresh devices, the program can miss what dominates later in life: increased error rates, degraded write performance, longer garbage collection cycles, and less forgiving margins during update windows.
As flash ages, the underlying chip behavior and error characteristics shift. Failures that never happened on new hardware can begin to show up during the update window.
Even without power loss, storage behavior can break timing assumptions. Garbage collection, compaction, and background flash work can introduce latency spikes during install or first boot.
If the system hits watchdog thresholds or misses timing windows, it can reset in a way that looks like a broken update.
From the outside, this looks like the update bricked the unit. From the inside, the update increased storage read and write pressure at the exact moment the system needed deterministic behavior.
Here, I/O refers to storage reads and writes.
As autonomy increases, tolerance for unpredictable latency drops. Determinism becomes part of reliability, not a performance preference.
A lot of update designs assume recovery will work. Mount behavior stays consistent. Corruption is detected early. Rollback returns the device to a known-good state.
Those assumptions become field incidents when they are not tested under the same failure conditions the fleet will experience: power interruptions during critical writes, degraded flash behavior, repeated update cycles, and long lifecycle write pressure.
A/B partitioning and a polished update agent handle the clean cases. They do not, on their own, guarantee that the small markers controlling the switch commit atomically and survive interruption. If the layer beneath cannot guarantee integrity and predictable recovery, OTA reliability remains an uphill battle.
This is not a substitute for root cause analysis. It helps teams prioritize where to look first.
Safe OTA updating is not only about encryption and signing. It is also about guaranteeing state integrity across the full update path.
A safe OTA design needs:
The storage layer is not the entire update system. But if storage cannot preserve critical state and recover predictably under interruption, the update framework and bootloader are forced to make decisions using state they may not be able to trust.
Most teams do not need more theory. They need a repeatable test plan with clear pass and fail criteria and artifacts they can take to program leadership.
Run controlled power interruptions at each stage and record the outcomes. The goal is simple: return to a known-good state without manual intervention.

To make this useful beyond a one-off run, define the known-good success conditions upfront. For example: boot to a usable runtime within X seconds, no repeated resets across Y boots, rollback completes within Z minutes, and no manual filesystem repair steps.
Force rollback triggers intentionally. Do not rely on rollback to work simply because the architecture includes it.
Useful tests include:
Pass criteria should include rollback completed without manual intervention, the known-good version is stable across repeated boots, and rollback does not loop even when the failure condition remains present.
Before running OTA validation, age devices with a workload that resembles reality.
For vehicles, this usually includes sustained logging, telemetry writes, normal application churn, and background write patterns that accumulate over months or years.
Then run the same power-cut matrix again.
This is where field-only failures show up early enough to fix. It also helps teams identify when the system is too sensitive to write amplification, garbage collection cycles, or flash wear patterns.
Measure boot and activation behavior under worst-case I/O pressure.
Useful measurements include:
If latency spikes cause resets, treat that as an OTA update safety issue. It is not something to postpone.
Capture the minimum set of artifacts that make failures actionable:
The point is not to collect every possible signal. The point is to capture enough evidence to separate delivery failures, update-framework failures, bootloader decisions, storage behavior, and application-state issues.
The fastest stability wins usually come from shrinking the window where critical state can be left inconsistent.
Start with:
Treat the smallest writes as some of the most important ones. Markers and checkpoints control the entire process. If those are not protected, even a valid image can become unusable because of a bad state decision.
A practical reliability goal is that recovery never depends on someone manually restoring a unit in the field. If an installation fails, the system should automatically return to a known-good version .
Wipe-and-reflash steps borrowed from consumer devices do not scale to a fleet, and they destroy the evidence needed to find the root cause. A vehicle program needs a repeatable method with clear pass and fail criteria instead.
If the update system cannot preserve trustworthy state during interruption, OTA update reliability becomes a recurring cost: field incidents, rework, repeated “cannot reproduce” investigations, and avoidable support burden.
Software-defined vehicles are updated often. Advanced driver assistance systems and physical AI systems depend more heavily on correct, persistent state to behave safely and predictably. More functions depend on reliable local persistence. More behavior depends on predictable data handling. Less tolerance exists for undefined recovery states and timing variances.
In this context, OTA updating is not only testing the update agent. It is testing whether the data path can preserve state, recover cleanly, and remain predictable under field conditions.
That is why storage integrity, bootloader behavior, update-framework logic, recovery behavior, and lifecycle validation all sit at the center of OTA update reliability.
Before your next OTA campaign reaches the fleet, make sure the storage layer can recover from every power cut, rollback, and aged-device edge case. Talk to our automotive storage experts about building this validation into your program.
Talk to an expertRELATED ARTICLES

In software-defined vehicles, zonal architecture storage requirements are really requirements for predictable behavior under stress — not peak speed. Here's...

Data corruption in software-defined vehicles doesn't always cause a crash. Why data reliability is now a strategic concern for SDV...

A fresh ECU can pass read, write, and reboot tests and still fail in the field. This guide covers what...

Automotive storage rarely fails outright — it drifts. Learn why vehicle storage performance degrades over time, which metrics actually matter,...
Suggested content for: